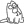RegEx-Pattern, zur Löschung von Leerstellen
- C#
- .NET (FX) 4.5–4.8
Sie verwenden einen veralteten Browser (%browser%) mit Sicherheitsschwachstellen und können nicht alle Funktionen dieser Webseite nutzen.
Hier erfahren Sie, wie einfach Sie Ihren Browser aktualisieren können.
Hier erfahren Sie, wie einfach Sie Ihren Browser aktualisieren können.
Es gibt 20 Antworten in diesem Thema. Der letzte Beitrag () ist von Facebamm.
-
-
Ich nehme an es geht immer noch um den HTML Parser?
Dafür ist der lexer verantwortlich, welcher leerzeichen solange nicht part von content einfach überspringt, das hat bessere Performance als du mit RegEx jemals schaffen kannst, außerdem durchläufst du das ganze sowieso schon -> noch besser für die performance...
Wenn du etwas haben willst, was dir den HTML Code schön ausgibt, sogenanntes pretty-print, dann macht man das idr indem man nach dem Parsing-Schritt aus dem Baum wieder HTML Code erzeugen lässt. So macht es mit ziemlicher Sicherheit auch Chrome. So macht es Visual Studio(autoformat). So macht es clang formatting Ich wollte auch mal ne total überflüssige Signatur:
Ich wollte auch mal ne total überflüssige Signatur:
---Leer--- -
-
-
-
@ErfinderDesRades das würde aber doch auch die aus dem Content nehmen.
Der soll doch aber hoffentlich so bleiben => Kann ja vom Ersteller des HTML-Skripts so gewollt sein.
Oder war das nicht die Vorgabe? -
@Snickbrack Richtig.
@ErfinderDesRades Das würde hierbei nichts bringen.
@Facebamm Lieben Dank
Eine alternative Lösung hier:
github.com/NET-D3v3l0p3r/HTMLR…ser/Analysis/Token.cs#L93
_Und Gott alleine weiß alles am allerbesten und besser. -
Ich hab mal nen test gemacht zu
.Replace("\r", "").Replace("\t", "").Replace("\n", "");und.Replace(text, replacement);
Spoiler anzeigen C#-Quellcode
- string a = " ";
- long count = 10_000_000;
- string pattern = "\\s{2,}";
- string replacement = "";
- Regex rgx = new Regex(pattern);
- Stopwatch watch = new Stopwatch();
- for (int l = 0; l < 1000; l += 1) {
- long aa, bb;
- watch.Restart();
- for (long i = 0; i < count; i += 1) {
- string b = a.Replace("\r", "").Replace("\t", "").Replace("\n", "");
- }
- watch.Stop();
- aa = watch.Elapsed.Ticks;
- watch.Restart();
- for (long i = 0; i < count; i += 1) {
- string b = rgx.Replace(a, replacement);
- }
- watch.Stop();
- bb = watch.Elapsed.Ticks;
- Console.WriteLine(aa);
- Console.WriteLine(bb);
- Console.WriteLine("-------------------------");
- }
das ergebniss lautet
replace... Regex.Replace 17754449 118736164 17507674 118452306 17990162 118214120 16959600 111611160 17627212 115210074 -
-
-
Nein, war es nicht.Snickbrack schrieb:
@ErfinderDesRades das würde aber doch auch die aus dem Content nehmen.
Der soll doch aber hoffentlich so bleiben => Kann ja vom Ersteller des HTML-Skripts so gewollt sein.
Oder war das nicht die Vorgabe?
Übrigens auch Facebams Replacing entfernt Spaces aussm Content.
Aber egal - meine Einlassung hatte eh den Sinn, aufzuzeigen, dass die Fragestellung nicht sonderlich sinnvoll war - und war ja eh nur eine Interesse-Frage.
-
ErfinderDesRades schrieb:
Übrigens auch Facebams Replacing entfernt Spaces aussm Content.
zu 100% würde man es schon hinbekommen aber dann wird der Regex hässlich, so wie der in meinem Projekt
@"(?:<td(?:[^>]+)?>([^<]+)[^\n]+\n[^>]+>((?:<em>)|[^<]+)<\/td>\n)|(?:<td(?:[^>]+)?><a\shref=""(?:\/cssref\/)?([^\/\""]+)\"">([^<]+)[^\n]+\n[^>]+>(<em>|<\/em>|[^<]+)+)"
Edit: aber wo zu will ich im Content zwei mal ein Leerzeichen in folge?
H|E|L|L|O| | |W|O|R|L|D=>H|E|L|L|O| |W|O|R|L|Dund deswegen\\s{2,} -
ErfinderDesRades schrieb:
Aber egal - meine Einlassung hatte eh den Sinn, aufzuzeigen, dass die Fragestellung nicht sonderlich sinnvoll war
Warum ?
Facebamm schrieb:
Edit: aber wo zu will ich im Content zwei mal ein Leerzeichen in folge
Stimmt.
_Und Gott alleine weiß alles am allerbesten und besser. -
Na, weil die Ersetzungen auch innerhalb der Contents sämtliche Spaces entfernen.φConst schrieb:
ErfinderDesRades schrieb:
Aber
egal - meine Einlassung hatte eh den Sinn, aufzuzeigen, dass die
Fragestellung nicht sonderlich sinnvoll war
Warum ?
φConst schrieb:
Siehst du?ErfinderDesRades schrieb:
Die Anforderung ist nun deutlich geändert, und die jetzige Lösung erfüllt nun nicht mehr, was in Post#1 durch das einzige gegebene Input-OutPut - Beispiel gefordert ist.
Facebamm dir also eine brauchbare Lösung geliefert, ohne dass du dazu eine brauchbare Anforderung formulieren musstest. -
-
3daycliff schrieb:
Zum Beispiel bei <pre>, <script>, <style>, (allen Attributen), Elemente mit der CSS-Eigenschaft white-space, etc.
was will ich da mit doppelten leerzeichen, ich bin doch froh, wenn mein code am ende komprimiert wird und der user nicht 100kb runterlanden muss sondern nur 80kb oder so O.O
selbst bei CSS-Eigenschaften kommen keine doppelten Leerzeichen vor, oder irre ich mich da?
wird dann einfach zu
selbst in der Anwendung
<|d|i|v| |i|d|=|"|p|r|o|p|e|r|t|i|e|I|D|"|>|H|e|l|l|o| |W|o|r|l|d|<|/|d|i|v|>wird zu, bzw. bleibt<|d|i|v| |i|d|=|"|p|r|o|p|e|r|t|i|e|I|D|"|>|H|e|l|l|o| |W|o|r|l|d|<|/|d|i|v|>
oder hab ich was übersehen? OO -
Facebamm schrieb:
ich bin doch froh, wenn mein code am ende komprimiert wird und der user nicht 100kb runterlanden muss sondern nur 80kb oder so O.O
Genau. Deswegen finde ich es eigentlich völlig nicht nötig wenn der Parser da irgendwas kürzt. Denn runtergeladen hat man die große Datei trotzdem und ändert sie nur ab.
Der Parser ist meiner Meinung nicht dafür da die arbeit des Entwicklers zu machen in dem er den HTML Code nochmal anpasst.
Wenn der HTML Code "scheiße" ist und nicht geparsed werden kann ist ja nicht der Parser schuld sondern der HTML Code Schreiber oder nicht? -
Bei Komprimierung sollte man schon zwischen lossy und lossless unterscheiden. Natürlich können manche Whitepsaces getrost ignoriert werden, aber halt nicht alle.
Im Post #1 und #5 finden sich z.B. ein paar Leerzeichen, die man nicht wegschmeißen will.
Bezüglich Attribute:<a onClick="foo('___');">und<style>.foo { background-image:url("pfad___mit___leerzeichen.png"); }</style>.
(Unterstrich hier mal als Leerzeichen interpretieren, weil die hier im Forum bei tt ignoriert werden...)
Über die Sinnhaftigkeit kann man natürlich streiten, der Standard erlaubt es aber. -
((?=\s{2,})(?!.*"\s|.*')\s*)|((?=\s{2,})(?!.*"|.*')\s*)so, der tut jetzt
der ist zwar auch nicht die Bombe aber besser wird es glaub net gehen
besser wird es glaub net gehen
regexr.com/3vs0c -
@Facebamm
Funktioniert nicht so recht:
regex101.com/r/EVBDTT/1
auch die Leerzeichen im String (id est: zwischen den beiden 'x') werden erkannt.
Anders als iterativ mit einem boolean (stringFound) ist es imo nicht realisierbar.
_Und Gott alleine weiß alles am allerbesten und besser.

-
Benutzer online 3
3 Besucher
-
Ähnliche Themen
-
 SAR-71 - - Sonstige Problemstellungen
SAR-71 - - Sonstige Problemstellungen -
filmee24 - - Sonstige Problemstellungen
-
henny - - Sonstige Problemstellungen
-
7 Benutzer haben hier geschrieben
- Facebamm (7)
- φConst (6)
- ErfinderDesRades (3)
- 3daycliff (2)
- xChRoNiKx (1)
- Snickbrack (1)
- jvbsl (1)