
Diskussionsfaden hier: Diskussionsthread: Git: Grundlagen, Branches, Best-Practices und mehr
Präambel
Moin zusammen,
Im Forum habe ich immer wieder gesehen, dass Leute sich nicht mit Git (oder Versionskontrolle allgemein) richtig auskennen, oder gar erst nichts davon wissen.
Egal ob ihr open- oder closed-source Software verwendet, ist eine vernünftige Versionskontrolle immer sinnvoll.
Es gibt diverse Produkte auf dem Markt, wie zum Beispiel Mercurial oder Subversion, die in diesem Thema allerdings nicht behandelt werden.
Viele Tipps und Informationen treffen genau so auf diese zu; die genaue Funktionsweisen unterscheiden sich allerdings teils massiv.
Ich bin nicht qualifiziert, Tipps und Informationen über andere Versionskontrollsysteme als Git zugeben und müsste genau so eine Suchmaschine verwenden, wie ihr.
Dieses Thema wird sich umfassend mit der Kommandozeilenanwendung
Grundsätzlich könnt ihr aber alles auch in GUI-Tools wie z.B. GitKraken anwenden.
Folgende Nomenklatur werde ich beim Schreiben von Befehlen verwenden:
01. Grundlagen - Was ist Git und wofür brauche ich das?
Git ist wie oben beschrieben ein Versionskontrollsystem. Es wird verwendet, um Änderungen in/an eurem Quellcode so zu verwalten, dass ihr zu jeder Zeit sehen könnt, wer was gebaut (oder auch verbaselt) hat.
Verwaltet werden eure Dateien in sogenannten Repositories. Diese sind einfache Ordner mit einigen bestimmten und wichtigen Dateien und Unterordnern, die Git für das Tracking benötigt.
Repositories bestehen aus zwei grundsätzlichen Stücken: local und remote.
Das local Repo ist das, was bei euch auf dem Rechner sitzt, womit ihr eure tägliche Arbeit erledigt.
Das remote liegt auf einem Git-Server und wird dort verwaltet/gehostet.
Diese beiden Repos können unabhängig voneinander geändert werden; diese Änderungen müssen jedoch zusammen synchronisiert (gemerged) werden. Dies geschieht entweder über Pull Requests, oder direkte Branch-Merges.
Diese strikte Trennung erlaubt es euch, dass ihr vorerst völlig unabhängig vom remote arbeiten könnt.
Um Dateien voneinander zu trennen und Unterschiede zwischen Versionen zu erkennen, bildet Git Hash-Werte der Dateien, die in dem Repository liegen und die "angemeldet" wurden.
02. Installation
Die Installation von Git ist auf allen großen Plattformen einfach. Für Linux und macOS ist Git in allen Packetverwaltungen; für neuere Versionen von Windows kann git mittels winget installiert werden (empfohlen).
In diesem Thread werde ich ausschließlich die Linux-Git-Variante verwenden. Die Befehle sind allerdings auf allen Plattformen gleich.
02.1 Klassiche Windows-Installation
Die klassische Variante, Git zu installieren, ist sich von git-scm.org die neueste Version des Git Bash herunterzuladen und unter Windows zu installieren.
Ich empfehle hier, Git ins System-PATH zu installieren, sodass ihr von jedem Powershell- oder CMD-Fenster darauf zugreifen könnt.
Für erfahrene Nutzer wird hier das Git Bash mitinstalliert, welches eine Linux-ähnliche Shell installiert, mit den POSIX-Standard-Toolset (vi, cat, less, etc.)
02.2 Moderne Windows-Installation
Moderne Versionen von Windows (Windows 10/11) bieten seit einiger Zeit WinGet an; dies ist ein Windows-eigenes Paketverwaltungstool, ähnlich zu NuGet.
WinGet kann über ein Powershell-Fenster verwendet werden:
02.3 Linux-Installation
Je nach Linux-Distro, werden unterschiedliche Paketverwalter verwendet.
Debian, Ubuntu, Linux Mint, ...:
Fedora, RHEL, CentOS:
Arch:
02.4 macOS-Installation
Auf macOS empfehle ich, Git über brew zu installieren:
03. Ein leeres Repository anlegen
Zuerst beschäftigen wir uns mit dem local Repo. Repos können lokal angelegt (initialisiert) werden und danach mit einem remote verknüpft werden.
Dies ist meine (persönliche) bevorzugte Variante, ein Repo anzulegen. So kann ich in Ruhe offline arbeiten und eine erste Version eines Projekts bauen, bevor es hochgeladen wird. So kann ich im Zweifel das Projekt folgenlos löschen und neubeginnen, sollte das nötig sein.
Zuerst suche ich mir einen Ort, an dem meine Repos angelegt werden sollen. Üblicherweise habe ich hierfür einen
Mit dem Befehl
Git wird dann einen gleichnamigen Ordner erstellen und darin folgende Ordner/Dateien anlegen:
Spoiler anzeigen
Zugleich wird auch der Haupt-"Branch" angelegt; in meinem Fall ist das "master" - je nach Konfiguration/Richtlinie könnte der bei euch erstellte Branch auch anders heißen, z.B. "main".
Für den Anfang müsst ihr nichts in dem
Hierin könnt ihr nun arbeiten und einen Prototypen erstellen. Git weiß allerdings noch nicht, welche Dateien es überwachen soll. Das wird später noch kommen.
Zuerst:
04. Das Local mit dem Remote verbinden
Nun habt ihr eurer local angelegt und möglicherweise auch Dateien abgelegt; nun wollt ihr dass euer Repo auch online (firmenintern oder z.B. bei GitHub) für andere (Personen, Computer, wie auch immer) sichtbar/verwendbar ist.
Hierzu müsst ihr zuerst bei eurem Git-Server ein Repository anlegen.
WICHTIG: Wenn ihr das Repo lokal angelegt habt, bevor es ein remote gab, dann seht davon ab, das Repo online zu initialisieren.
In dem u.a. Screenshot seht ihr, dass ich alle Optionen abgewählt habe.
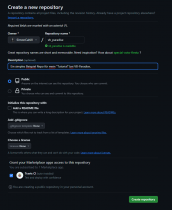
Tipp: Der Name eures remotes muss nicht dem gleichen, was ihr als local erstellt habt. Das ist Git völlig egal.
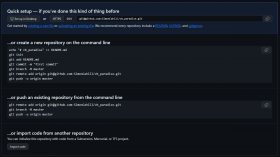
GitHub zeigt euch netterweise direkt an, welche Befehle ihr ausführen müsst, um die beiden Repos miteinander zu verknüpfen.
Grundsätzlich braucht ihr nur diesen Befehl, solltet ihr euch für diese Variante entschieden haben:
Nun sind beide Repos miteinander verknüpft und können miteinander synchronisiert werden.
05. Ein bestehendes oder neues Repo klonen
Neben der oben aufgeführten Variante, kann man bei GitHub auch ein Repo initialisieren, sodass man das Repo einfach klonen kann.
Das funktioniert dann sowohl für neue Repos, als auch für bestehende Repos, die möglicherweise sogar noch Submodule verwenden.
Um ein bestehendes Repo zu klonen, müsst ihr nur folgenden Befehl ausführen:
Wie ihr seht, habe ich noch den Switch
Da ich das vorhin erstellte (nicht initialisierte) Repo erneut geklont habe, gibt git mir eine Warnung, dass in dem Repo nichts enthalten ist. Das ist nicht weiter schlimm und kann in den meisten Fällen ignoriert werden.
06. Irrelevante Dateien ignorieren
Git erlaubt es, eine vielzahl an verschiedenen Dateien zu indizieren und verwalten. Dazu gehören Bilder, BLOBs, Binaries in Form von Object-Code oder Anwendungen und vieles, vieles mehr.
Es ist jedoch nicht immer sinnvoll, alle Dateien von Git verwalten zu lassen.
Folgende Regeln sollten beachtet werden, damit ihr euer Repo nicht zumüllt und am Ende niemand unnötigen Schrott herunterladen muss, den er sowieso beim nächsten Build ersetzt.
Hierzu bietet git sog.
Datei-Struktur:
Regeln (Best Practice)/Zu ignorierende Dateien/Ordner:
In einem leeren Repository, wird git erstmal keine Dateien überwachen. Das ist, damit ihr entscheiden könnt, welche Dateien versioniert werden müssen und welche nicht.
Git kann entweder einzelne oder gleichzeitig mehrere Dateien (und Ordner) zur Überwachung aufnehmen.
Werden Dateien zur Überwachung hinzugefügt, werden diese allerdings nicht gleich gehashed und diese sind dann auch nicht in dem remote.
Alle Änderungen sind in dem local und können sehr einfach reversiert werden.
07.1 Einzelne Dateien zur Versionskontrolle aufnehmen
Mit dem Befehl
07.2 Mehrere Dateien zur Versionskontrolle hinzufügen
Den obigen Befehl kann mit beliebig vielen Dateien erweitert werden, um gleichzeitig mehrere Dateien hinzuzufügen:
07.3 Alle Dateien zur Versionskontrolle hinzufügen
Wenn ihr eure
08. Dateien committen
Nun habt ihr eure Dateien hinzugefügt, die wichtigsten Schritte sind erledigt. Nun müsst ihr mit git ein Hash der Datei(en) erstellen. So könnt ihr dann später die Unterschiede zwischen den Versionen sehen.
Dazu müsst ihr einen "Commit" durchführen; dieser kann entweder mit einzelnen Dateien oder über das ganze Repo erfolgen.
Ein Commit beinhaltet nicht nur die Änderungen an den Dateien, sondern auch ein Kommentar von euch, in dem ihr beschreiben könnt, was ihr seit dem letzten Stand gemacht habt.
So könnt ihr (oder andere Entwickler) auf einem Blick sehen, was geschehen ist, ohne dass die sich mühselig durch alle Dateiänderungen fuchsen müssen.
Der Commitbefehl hat folgende Struktur:
Ihr könnt den
Das sieht z.B. so aus:
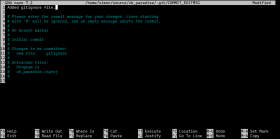
Wir ihr seht, sind unten einige Zeilen mit Rauten. Diese werden von git ignoriert und sind nur zu eurer Info.
Alle Zeilen, die nicht mit einer Raute beginnen, sind dann eure Commitnachricht. Ich persönlich schreibe sie oben weil es einfacher und schneller geht.
09. Repo mit dem Server synchronisieren
Eure Dateien sind soweit, dass sie zum Server übertragen werden können.
Hierzu könnt ihr nun den Befehl
Wir ihr seht, wurde auf dem Server nun auch ein neuer Branch erstellt, der eure Änderungen enthält.
Für alle Branches und Tags die ihr erstellt ist das Verfahren gleich oder sehr ähnlich.
10. Was genau sind Branches und wofür brauche ich sie?
Grundsätzlich möchte man in der Entwicklung seinen funktionalen Stand von dem instabilen Stand trennen; mit git geht dies mittels Branches.
Ihr müsst euch das Repo wie ein Baum vorstellen.
Anbei ein Beispielbild aus einem meiner Repos:
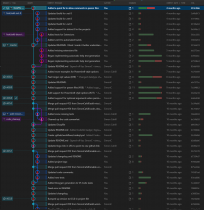
Ihr habt einen "Stamm", also einen Hauptzweig für euren Code.
Nach Best Practice wird in diesem Branch nicht entwickelt. (Bei Bedarf würde ich noch einen Beitrag erstellen, wo Branching-Modelle genauer erklärt würden!)
Stattdessen, zweigt ihr von dem Hauptzweig ab und führt die nach eurer Entwicklungsphase wieder zusammen.
Dieses Vorgehen hat den Vorteil, dass eure Entwicklungsversionen von dem stabilen Zweig entfernt sind und dort auch nichts kaputtmachen können.
Branches können jederzeit erstellt und wieder gelöscht werden.
Einige Regeln sollte man noch berücksichtigen:
Um unter git einen Branch zu erstellen, führt folgenden Befehl aus:
Wichtig zu wissen ist, dass git immer ab genau dem Punkt einen neuen Branch erstellt, an dem ihr euch befindet! Habt ihr ein Branch oder Tag ausgecheckt, wird genau der aktuelle, lokale, Stand als Abzweigpunkt verwendet!
10.2 Zwischen Branches wechseln
Es kann immer mal vorkommen, dass man zwischen Branches wechseln muss. Hierfür könnt ihr den Befehl:
10.3 Alle Branches anzeigen
Um alle Branches anzuzeigen, führt den Befehl
Git wird euch den Branch, auf dem ihr euch aktuell befindet, mit einem Stern (*) markieren.
10.4 Branches zusammenführen
Sollen zwei Branches zusammengeführt werden, müssen erstmal alle Änderungen committed werden.
Ist das geschehen, ist es am einfachsten, man wechselt zum Zielbranch, vor dem Merge.
Sobald das getan ist, kann ein beliebiger Branch in den aktuellen mit dem Befehl
Vorerst-Abschluss
Ich hoffe ich konnte euch hiermit einiges erklären und zeigen.
Je nachdem, wie das ankommt, würde ich es mit euren Fragen und Anregungen erweitern. Git hat noch sehr viel mehr zu bieten, wie z.B. Tags, den Stash, Pull Requests und vieles mehr.
Bis dahin hoffe ich, dass das nicht zu viel Text war!
Habt ihr Verbesserungsvorschläge, schreibt mich gerne an und ich werde sie übernehmen, wenn sinnvoll.
Happy Coding!
Präambel
Moin zusammen,
Im Forum habe ich immer wieder gesehen, dass Leute sich nicht mit Git (oder Versionskontrolle allgemein) richtig auskennen, oder gar erst nichts davon wissen.
Egal ob ihr open- oder closed-source Software verwendet, ist eine vernünftige Versionskontrolle immer sinnvoll.
Es gibt diverse Produkte auf dem Markt, wie zum Beispiel Mercurial oder Subversion, die in diesem Thema allerdings nicht behandelt werden.
Viele Tipps und Informationen treffen genau so auf diese zu; die genaue Funktionsweisen unterscheiden sich allerdings teils massiv.
Ich bin nicht qualifiziert, Tipps und Informationen über andere Versionskontrollsysteme als Git zugeben und müsste genau so eine Suchmaschine verwenden, wie ihr.
Dieses Thema wird sich umfassend mit der Kommandozeilenanwendung
git auseinandersetzen!Grundsätzlich könnt ihr aber alles auch in GUI-Tools wie z.B. GitKraken anwenden.
Folgende Nomenklatur werde ich beim Schreiben von Befehlen verwenden:
01. Grundlagen - Was ist Git und wofür brauche ich das?
Git ist wie oben beschrieben ein Versionskontrollsystem. Es wird verwendet, um Änderungen in/an eurem Quellcode so zu verwalten, dass ihr zu jeder Zeit sehen könnt, wer was gebaut (oder auch verbaselt) hat.
Verwaltet werden eure Dateien in sogenannten Repositories. Diese sind einfache Ordner mit einigen bestimmten und wichtigen Dateien und Unterordnern, die Git für das Tracking benötigt.
Repositories bestehen aus zwei grundsätzlichen Stücken: local und remote.
Das local Repo ist das, was bei euch auf dem Rechner sitzt, womit ihr eure tägliche Arbeit erledigt.
Das remote liegt auf einem Git-Server und wird dort verwaltet/gehostet.
Diese beiden Repos können unabhängig voneinander geändert werden; diese Änderungen müssen jedoch zusammen synchronisiert (gemerged) werden. Dies geschieht entweder über Pull Requests, oder direkte Branch-Merges.
Diese strikte Trennung erlaubt es euch, dass ihr vorerst völlig unabhängig vom remote arbeiten könnt.
Um Dateien voneinander zu trennen und Unterschiede zwischen Versionen zu erkennen, bildet Git Hash-Werte der Dateien, die in dem Repository liegen und die "angemeldet" wurden.
02. Installation
Die Installation von Git ist auf allen großen Plattformen einfach. Für Linux und macOS ist Git in allen Packetverwaltungen; für neuere Versionen von Windows kann git mittels winget installiert werden (empfohlen).
In diesem Thread werde ich ausschließlich die Linux-Git-Variante verwenden. Die Befehle sind allerdings auf allen Plattformen gleich.
02.1 Klassiche Windows-Installation
Die klassische Variante, Git zu installieren, ist sich von git-scm.org die neueste Version des Git Bash herunterzuladen und unter Windows zu installieren.
Ich empfehle hier, Git ins System-PATH zu installieren, sodass ihr von jedem Powershell- oder CMD-Fenster darauf zugreifen könnt.
Für erfahrene Nutzer wird hier das Git Bash mitinstalliert, welches eine Linux-ähnliche Shell installiert, mit den POSIX-Standard-Toolset (vi, cat, less, etc.)
02.2 Moderne Windows-Installation
Moderne Versionen von Windows (Windows 10/11) bieten seit einiger Zeit WinGet an; dies ist ein Windows-eigenes Paketverwaltungstool, ähnlich zu NuGet.
WinGet kann über ein Powershell-Fenster verwendet werden:
02.3 Linux-Installation
Je nach Linux-Distro, werden unterschiedliche Paketverwalter verwendet.
Debian, Ubuntu, Linux Mint, ...:
$ sudo apt install gitFedora, RHEL, CentOS:
$ sudo yum install gitArch:
$ sudo pacman -S git02.4 macOS-Installation
Auf macOS empfehle ich, Git über brew zu installieren:
% brew install git03. Ein leeres Repository anlegen
Zuerst beschäftigen wir uns mit dem local Repo. Repos können lokal angelegt (initialisiert) werden und danach mit einem remote verknüpft werden.
Dies ist meine (persönliche) bevorzugte Variante, ein Repo anzulegen. So kann ich in Ruhe offline arbeiten und eine erste Version eines Projekts bauen, bevor es hochgeladen wird. So kann ich im Zweifel das Projekt folgenlos löschen und neubeginnen, sollte das nötig sein.
Zuerst suche ich mir einen Ort, an dem meine Repos angelegt werden sollen. Üblicherweise habe ich hierfür einen
source-Ordner unter meinem Benutzerverzeichnis: /home/simon/sourceMit dem Befehl
git init <project_name> kann ich nun ein frisches Git-Repo anlegen.Git wird dann einen gleichnamigen Ordner erstellen und darin folgende Ordner/Dateien anlegen:
Quellcode
- simon@ODIN: /home/simon/source
- ➜ git init vb_paradise
- Initialized empty Git repository in /home/simon/source/vb_paradise/.git/
- .:
- total 12K
- drwxr-xr-x 3 simon simon 4.0K Jan 9 15:58 .
- drwxr-xr-x 33 simon simon 4.0K Jan 9 15:58 ..
- drwxr-xr-x 7 simon simon 4.0K Jan 9 15:58 .git
- ./.git:
- total 40K
- drwxr-xr-x 7 simon simon 4.0K Jan 9 15:58 .
- drwxr-xr-x 3 simon simon 4.0K Jan 9 15:58 ..
- -rw-r--r-- 1 simon simon 23 Jan 9 15:58 HEAD
- drwxr-xr-x 2 simon simon 4.0K Jan 9 15:58 branches
- -rw-r--r-- 1 simon simon 92 Jan 9 15:58 config
- -rw-r--r-- 1 simon simon 73 Jan 9 15:58 description
- drwxr-xr-x 2 simon simon 4.0K Jan 9 15:58 hooks
- drwxr-xr-x 2 simon simon 4.0K Jan 9 15:58 info
- drwxr-xr-x 4 simon simon 4.0K Jan 9 15:58 objects
- drwxr-xr-x 4 simon simon 4.0K Jan 9 15:58 refs
- ./.git/branches:
- total 8.0K
- drwxr-xr-x 2 simon simon 4.0K Jan 9 15:58 .
- drwxr-xr-x 7 simon simon 4.0K Jan 9 15:58 ..
- ./.git/hooks:
- total 68K
- drwxr-xr-x 2 simon simon 4.0K Jan 9 15:58 .
- drwxr-xr-x 7 simon simon 4.0K Jan 9 15:58 ..
- -rwxr-xr-x 1 simon simon 478 Jan 9 15:58 applypatch-msg.sample
- -rwxr-xr-x 1 simon simon 896 Jan 9 15:58 commit-msg.sample
- -rwxr-xr-x 1 simon simon 4.7K Jan 9 15:58 fsmonitor-watchman.sample
- -rwxr-xr-x 1 simon simon 189 Jan 9 15:58 post-update.sample
- -rwxr-xr-x 1 simon simon 424 Jan 9 15:58 pre-applypatch.sample
- -rwxr-xr-x 1 simon simon 1.7K Jan 9 15:58 pre-commit.sample
- -rwxr-xr-x 1 simon simon 416 Jan 9 15:58 pre-merge-commit.sample
- -rwxr-xr-x 1 simon simon 1.4K Jan 9 15:58 pre-push.sample
- -rwxr-xr-x 1 simon simon 4.8K Jan 9 15:58 pre-rebase.sample
- -rwxr-xr-x 1 simon simon 544 Jan 9 15:58 pre-receive.sample
- -rwxr-xr-x 1 simon simon 1.5K Jan 9 15:58 prepare-commit-msg.sample
- -rwxr-xr-x 1 simon simon 2.8K Jan 9 15:58 push-to-checkout.sample
- -rwxr-xr-x 1 simon simon 3.6K Jan 9 15:58 update.sample
- ./.git/info:
- total 12K
- drwxr-xr-x 2 simon simon 4.0K Jan 9 15:58 .
- drwxr-xr-x 7 simon simon 4.0K Jan 9 15:58 ..
- -rw-r--r-- 1 simon simon 240 Jan 9 15:58 exclude
- ./.git/objects:
- total 16K
- drwxr-xr-x 4 simon simon 4.0K Jan 9 15:58 .
- drwxr-xr-x 7 simon simon 4.0K Jan 9 15:58 ..
- drwxr-xr-x 2 simon simon 4.0K Jan 9 15:58 info
- drwxr-xr-x 2 simon simon 4.0K Jan 9 15:58 pack
- ./.git/objects/info:
- total 8.0K
- drwxr-xr-x 2 simon simon 4.0K Jan 9 15:58 .
- drwxr-xr-x 4 simon simon 4.0K Jan 9 15:58 ..
- ./.git/objects/pack:
- total 8.0K
- drwxr-xr-x 2 simon simon 4.0K Jan 9 15:58 .
- drwxr-xr-x 4 simon simon 4.0K Jan 9 15:58 ..
- ./.git/refs:
- total 16K
- drwxr-xr-x 4 simon simon 4.0K Jan 9 15:58 .
- drwxr-xr-x 7 simon simon 4.0K Jan 9 15:58 ..
- drwxr-xr-x 2 simon simon 4.0K Jan 9 15:58 heads
- drwxr-xr-x 2 simon simon 4.0K Jan 9 15:58 tags
- ./.git/refs/heads:
- total 8.0K
- drwxr-xr-x 2 simon simon 4.0K Jan 9 15:58 .
- drwxr-xr-x 4 simon simon 4.0K Jan 9 15:58 ..
- ./.git/refs/tags:
- total 8.0K
- drwxr-xr-x 2 simon simon 4.0K Jan 9 15:58 .
- drwxr-xr-x 4 simon simon 4.0K Jan 9 15:58 ..
Zugleich wird auch der Haupt-"Branch" angelegt; in meinem Fall ist das "master" - je nach Konfiguration/Richtlinie könnte der bei euch erstellte Branch auch anders heißen, z.B. "main".
Für den Anfang müsst ihr nichts in dem
.git-Ordner machen. Wichtig zu wissen ist nur: hier speichert Git alle Hashes eurer Dateien, Branches und weitere Meta-Infos zum Repo ab, wie z.B. wo der remote liegt.Hierin könnt ihr nun arbeiten und einen Prototypen erstellen. Git weiß allerdings noch nicht, welche Dateien es überwachen soll. Das wird später noch kommen.
Zuerst:
04. Das Local mit dem Remote verbinden
Nun habt ihr eurer local angelegt und möglicherweise auch Dateien abgelegt; nun wollt ihr dass euer Repo auch online (firmenintern oder z.B. bei GitHub) für andere (Personen, Computer, wie auch immer) sichtbar/verwendbar ist.
Hierzu müsst ihr zuerst bei eurem Git-Server ein Repository anlegen.
WICHTIG: Wenn ihr das Repo lokal angelegt habt, bevor es ein remote gab, dann seht davon ab, das Repo online zu initialisieren.
In dem u.a. Screenshot seht ihr, dass ich alle Optionen abgewählt habe.
Tipp: Der Name eures remotes muss nicht dem gleichen, was ihr als local erstellt habt. Das ist Git völlig egal.
GitHub zeigt euch netterweise direkt an, welche Befehle ihr ausführen müsst, um die beiden Repos miteinander zu verknüpfen.
Grundsätzlich braucht ihr nur diesen Befehl, solltet ihr euch für diese Variante entschieden haben:
Nun sind beide Repos miteinander verknüpft und können miteinander synchronisiert werden.
05. Ein bestehendes oder neues Repo klonen
Neben der oben aufgeführten Variante, kann man bei GitHub auch ein Repo initialisieren, sodass man das Repo einfach klonen kann.
Das funktioniert dann sowohl für neue Repos, als auch für bestehende Repos, die möglicherweise sogar noch Submodule verwenden.
Um ein bestehendes Repo zu klonen, müsst ihr nur folgenden Befehl ausführen:
Wie ihr seht, habe ich noch den Switch
--recursive übergeben. Das sorgt dafür, dass das Repo und alle Submodule (weitere Repos, innerhalb des Hauptrepos) mitgeklont werden. So spart man sich am Ende dumme Fehler, wenn gewisse Ordner direkt nach dem Klonen leer sind.Da ich das vorhin erstellte (nicht initialisierte) Repo erneut geklont habe, gibt git mir eine Warnung, dass in dem Repo nichts enthalten ist. Das ist nicht weiter schlimm und kann in den meisten Fällen ignoriert werden.
06. Irrelevante Dateien ignorieren
Git erlaubt es, eine vielzahl an verschiedenen Dateien zu indizieren und verwalten. Dazu gehören Bilder, BLOBs, Binaries in Form von Object-Code oder Anwendungen und vieles, vieles mehr.
Es ist jedoch nicht immer sinnvoll, alle Dateien von Git verwalten zu lassen.
Folgende Regeln sollten beachtet werden, damit ihr euer Repo nicht zumüllt und am Ende niemand unnötigen Schrott herunterladen muss, den er sowieso beim nächsten Build ersetzt.
Hierzu bietet git sog.
.gitignore-Dateien an. Diese können in jeden Ordner innerhalb des Repos angelegt werden und gelten dann für den und alle Unterordner.Datei-Struktur:
Quellcode
- # Kommentare müssen mit einer Raute am Anfang der Zeile beginnen und sind immer nur eine Zeile lang
- # Mehrzeilige Kommentare bestehen aus einzeiligen Kommentaren.
- # Es können ganze Ordner ignoriert werden:
- bin/
- obj/
- # Wenn ihr ein Ordner habt, der grundsätzlich ignoriert werden soll, wo aber einzelne Dateien benötigt werden, schreibt diese mit einem !
- # Dann wird die Datei in dem Ordner weiter mitversioniert.
- # In diesem Beispiel: Einstellungen für VS Code was C++-Entwicklung angeht.
- # Alle anderen Dateien werden von git ignoriert.
- !.vscode/c_cpp_properties.json
- # Oder auch einzelne Dateien:
- meine_textdatei_mit_meinem_vorhaben.txt
Regeln (Best Practice)/Zu ignorierende Dateien/Ordner:
- Unwichtige oder persönliche IDE Einstellungen sollten nicht mitversioniert werden
- Deine Lieblingsfarben interessieren mich nicht
- Ausnahmen: Coding-Richtlinien, Build-/Debug-Einstellungen
- Build-Artefakte
- Liefer sie nicht mit, die kann ich mir selber bauen
- Test-/Debug-Daten
- Ausnahmen: Daten, die zwingend für deine automatisierten Tests notwendig sind
- Test-Daten sollten nach Möglichkeit prozedural generiert werden
In einem leeren Repository, wird git erstmal keine Dateien überwachen. Das ist, damit ihr entscheiden könnt, welche Dateien versioniert werden müssen und welche nicht.
Git kann entweder einzelne oder gleichzeitig mehrere Dateien (und Ordner) zur Überwachung aufnehmen.
Werden Dateien zur Überwachung hinzugefügt, werden diese allerdings nicht gleich gehashed und diese sind dann auch nicht in dem remote.
Alle Änderungen sind in dem local und können sehr einfach reversiert werden.
07.1 Einzelne Dateien zur Versionskontrolle aufnehmen
Mit dem Befehl
$ git add <filename> könnt ihr einzelne Dateien zur Versionskontrolle hinzufügen.07.2 Mehrere Dateien zur Versionskontrolle hinzufügen
Den obigen Befehl kann mit beliebig vielen Dateien erweitert werden, um gleichzeitig mehrere Dateien hinzuzufügen:
$ git add <filename0> [<filename1> [<filename2> [...]]]07.3 Alle Dateien zur Versionskontrolle hinzufügen
Wenn ihr eure
.gitignore richtig eingestellt habt, könnt ihr bedenkenfrei alle übrigens Dateien zur Versionskontrolle hinzufügen: $ git add --all08. Dateien committen
Nun habt ihr eure Dateien hinzugefügt, die wichtigsten Schritte sind erledigt. Nun müsst ihr mit git ein Hash der Datei(en) erstellen. So könnt ihr dann später die Unterschiede zwischen den Versionen sehen.
Dazu müsst ihr einen "Commit" durchführen; dieser kann entweder mit einzelnen Dateien oder über das ganze Repo erfolgen.
Ein Commit beinhaltet nicht nur die Änderungen an den Dateien, sondern auch ein Kommentar von euch, in dem ihr beschreiben könnt, was ihr seit dem letzten Stand gemacht habt.
So könnt ihr (oder andere Entwickler) auf einem Blick sehen, was geschehen ist, ohne dass die sich mühselig durch alle Dateiänderungen fuchsen müssen.
Der Commitbefehl hat folgende Struktur:
Ihr könnt den
-m "" Parameter weglassen, dann werdet ihr allerdings zu einem Texteditor weitergeleitet, wo ihr die Commitnachricht bearbeiten müsst.Das sieht z.B. so aus:
Wir ihr seht, sind unten einige Zeilen mit Rauten. Diese werden von git ignoriert und sind nur zu eurer Info.
Alle Zeilen, die nicht mit einer Raute beginnen, sind dann eure Commitnachricht. Ich persönlich schreibe sie oben weil es einfacher und schneller geht.
09. Repo mit dem Server synchronisieren
Eure Dateien sind soweit, dass sie zum Server übertragen werden können.
Hierzu könnt ihr nun den Befehl
$ git push verwenden:Quellcode
- simon@ODIN: /home/simon/source/vb_paradise git:(master) ✗
- ➜ git push
- Enumerating objects: 3, done.
- Counting objects: 100% (3/3), done.
- Writing objects: 100% (3/3), 229 bytes | 229.00 KiB/s, done.
- Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
- To github.com:SimonCahill/vb_paradise.git
- * [new branch] master -> master
Wir ihr seht, wurde auf dem Server nun auch ein neuer Branch erstellt, der eure Änderungen enthält.
Für alle Branches und Tags die ihr erstellt ist das Verfahren gleich oder sehr ähnlich.
10. Was genau sind Branches und wofür brauche ich sie?
Grundsätzlich möchte man in der Entwicklung seinen funktionalen Stand von dem instabilen Stand trennen; mit git geht dies mittels Branches.
Ihr müsst euch das Repo wie ein Baum vorstellen.
Anbei ein Beispielbild aus einem meiner Repos:
Ihr habt einen "Stamm", also einen Hauptzweig für euren Code.
Nach Best Practice wird in diesem Branch nicht entwickelt. (Bei Bedarf würde ich noch einen Beitrag erstellen, wo Branching-Modelle genauer erklärt würden!)
Stattdessen, zweigt ihr von dem Hauptzweig ab und führt die nach eurer Entwicklungsphase wieder zusammen.
Dieses Vorgehen hat den Vorteil, dass eure Entwicklungsversionen von dem stabilen Zweig entfernt sind und dort auch nichts kaputtmachen können.
Branches können jederzeit erstellt und wieder gelöscht werden.
Einige Regeln sollte man noch berücksichtigen:
- Verwendet sinnvolle Namen für eure Branches!
- Je nachdem, ob es sich um einen Entwicklungs-, Hotfix- oder PoC-Branch handelt, verwendet andere Präfixe
- feat/mein-feature-branch
- fix/mein-reparier-branch
- poc/mein-proof-of-concept-branch
- feat/mein-feature-branch
- Schreibt Branchnamen im lower-kebap-case und haltet es einheitlich
- So könnt ihr Branchnamen von z.B. Tags unterscheiden
- So könnt ihr Branchnamen von z.B. Tags unterscheiden
- Vermeidet ewige Branches.
- Branches sollten möglichst kurzlebig sein und so schnell wie möglich zurück in den Hauptzweig geführt werden, sodass die Unterschiede zwischen den Codebasen nicht zu groß werden, dass ein Merge nicht sinnvoll machbar ist!
Um unter git einen Branch zu erstellen, führt folgenden Befehl aus:
git checkout -b <"new_branch_name">.Wichtig zu wissen ist, dass git immer ab genau dem Punkt einen neuen Branch erstellt, an dem ihr euch befindet! Habt ihr ein Branch oder Tag ausgecheckt, wird genau der aktuelle, lokale, Stand als Abzweigpunkt verwendet!
10.2 Zwischen Branches wechseln
Es kann immer mal vorkommen, dass man zwischen Branches wechseln muss. Hierfür könnt ihr den Befehl:
git checkout <branch_name> verwenden.10.3 Alle Branches anzeigen
Um alle Branches anzuzeigen, führt den Befehl
git branch.Git wird euch den Branch, auf dem ihr euch aktuell befindet, mit einem Stern (*) markieren.
10.4 Branches zusammenführen
Sollen zwei Branches zusammengeführt werden, müssen erstmal alle Änderungen committed werden.
Ist das geschehen, ist es am einfachsten, man wechselt zum Zielbranch, vor dem Merge.
Sobald das getan ist, kann ein beliebiger Branch in den aktuellen mit dem Befehl
git merge <branch_name> geführt werden.Vorerst-Abschluss
Ich hoffe ich konnte euch hiermit einiges erklären und zeigen.
Je nachdem, wie das ankommt, würde ich es mit euren Fragen und Anregungen erweitern. Git hat noch sehr viel mehr zu bieten, wie z.B. Tags, den Stash, Pull Requests und vieles mehr.
Bis dahin hoffe ich, dass das nicht zu viel Text war!
Habt ihr Verbesserungsvorschläge, schreibt mich gerne an und ich werde sie übernehmen, wenn sinnvoll.
Happy Coding!
Quellcode lizensiert unter CC by SA 2.0 (Creative Commons Share-Alike)
Meine Firma: Procyon Systems
Selbstständiger Softwareentwickler & IT-Techniker.
Meine Firma: Procyon Systems
Selbstständiger Softwareentwickler & IT-Techniker.
Dieser Beitrag wurde bereits 2 mal editiert, zuletzt von „siycah“ ()

