
So, weil ich allmählich mit utube besser klar komme, habich meine 4-Views-Theorie mal in Videos veranschaulicht.
Vorraussetzung zum Verständnis ist ein Verständnis der relationalen Datenmodellierung, also was bedeutet Beziehung (alias "Relation"), was ist eine 1:n-Relation, was eine m:n-Relation, und warum ist relationale Datenmodellierung so viel toller als wenn man einfach Objekte schafft, die selbst wieder Listen weiterer Objekte enthalten.
Vier-Views-Theorie
naja, ich unterscheide 4 grundlegende Typen, wie man komplexe Daten präsentieren kann (also anzeigen + der User kann was damit tun):
Jedenfalls wesentlich an den Views ist auch, dass man sie nach Belieben und Erfordernis miteinander kombiniert, und damit eine unerhörte Vielfalt an Präsentations-Möglichkeiten erhält.
Beispiel-Datenmodell
Man denke an ein Kaufhaus - extrem verkürzt: es gibt Artikel, ArtikelKategorien und Lieferanten - mehr nicht.
Das Modell ist auch schnell notiert:
oder als Dataset-Bildle:
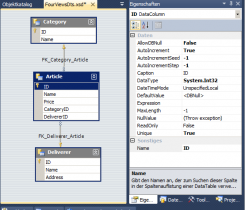
Artikel ist sowohl den Kategorien als auch den Lieferanten untergeordnet: eine Kategorie enthält viele Artikel, ein Lieferant liefert viele Artikel.
Und andersrum betrachtet: jeder Artikel verweist mittels ForeignKey auf genau eine Kategorie, und auf genau einen Lieferanten.
Also zwei 1:n-Relationen mit gemeinsamer untergeordneter Tabelle, und sowas ist inne Datenbänkerei halt als m:n-Relation bekannt (eine Kategorie enthält Artikel vieler Lieferanten, und ein Lieferant liefert Artikel vieler Kategorien)
Wie gesagt: Wer diesen Begrifflichkeiten (1:n - m:n - Relation) nicht folgen kann: Relationale Datenmodellierung
Andernfalls mögen die folgenden Filmle eine vielleicht beeindruckende Zielvorstellung und Motivation geben. Aber praxisrelevant, also dass man die gezeigten Features in eigenen Projekten dienstbar hat, ist das erst, wenn das mit den Relationen richtig verstanden ist, weil darauf baut es auf.
Übrigens jede nicht-triviale Sql-Datenbank baut ebenfalls darauf auf.
Die Filme
Film I - Datamodel Hier wird das Datenmodell aufgesetzt, und auch die Datengenerier-Methode angedeutet, die dieses Modell adäquat füllt, insbesondere die Artikel-Table, (nämlich aus zwei sich teilweise überschneidenden Lieferanten- und Kategorie-Gruppen).
Die Generiererei ist eiglich zu kompliziert, ums im Film gleich zu kapieren, aber sie ist im Code-Download drinne, und ist mir wichtig zu zeigen, dass das typisierte Dataset über einen Haufen speziell generierte Methoden verfügt, mit denen man eigentlich jeden Standard-Zugriff in streng typisierter Manier ausführen kann - natürlich auch das Adden von neu generierten typisierten DataRows.
Also beim Zugriff aufs Dataset willich nix sehen mit:
odersowas (achtung - Beispiel ausse Praxis):
Also gugget den typisierten Zugriff im SampleCode an, und guckt die 3 Tabellen auch im ObjectBrowser an, was da alles an typisierten Kram drinnesteckt, sodass man die untypisierten Typen
Wir haben
Film II - RawView erstellt eine erste Roh-Ansicht aller 3 Tabellen, ohne jede Fisematente. Sowas braucht man eiglich immer, um schnell zu gugge, ob Daten da sind, oder um halt mal welche eingeben zu können.
Film III - JoiningView zeigt endlich den ersten der 4 Views, nämlich den JoiningView, also ein Article-DatagridView, bei dem ComboboxColumns Werte der übergeordneten Tabellen mit "hinein-joinen" (nämlich
Der Name "JoiningView" ist in Analogie zur Sql-InnerJoin-Abfrage gewählt, denn ein JoiningView zeigt genau die Daten an, die auch ein Sql-InnerJoin über mehrere Tabellen anliefern würde.
Er leistet aber wesentlich mehr, denn er ermöglicht dem User, Änderungen vorzunehmen und zurückzuspeichern - eine Option, die beim Sql-Innerjoin prinzipiell ausgeschlossen ist.
Film IV - DetailView zeigt eine schlichte Liste der Artikel(-Namen), und man kann einen Artikel auswählen, und bekommt all seine Properties in ausführlichen Einzel-Controls präsentiert.
Der hier gezeigte DetailView geht aber über einen schlichten DetailView hinaus, denn er enthält auch einen Joining-Part, nämlich Comboboxen, die (wieder)
Es handelt sich hier also um einen kombinierten View, und das ist ebenfalls Kern-Aussage der 4 View-Theorie, nämlich dass die vier Grundtypen beliebig kombinierbar sind.
Film V - ParentChild-View zeigt links alle Kategorien, und rechts alle Artikel, die der links gewählten Kategorie angehören.
Obwohl sehr einfach zusammengeklickst, beeindruckt dieser View doch mehr als ein Joining-View, weil über das Databinding werden immer alle angezeigten Artikel ausgetauscht, wenn man eine annere Category wählt.
FilmVI - m:n-View - habe ich gleich in beide Richtungen implementiert: Einmal kannman eine Kategorie wählen, und sieht alle Artikel, inklusive Lieferant.
Beim View in Gegenrichtung kann man dann einen Lieferanten wählen, und sieht alle Artikel, die er liefert, inklusive ihrer jeweiligen Kategorie.
Son m:n-View kombiniert also den ParentChildView (Film V) mittm JoiningView (Film III).
Weiterführende Links
Hier die Sample-Solution der Videos als Download:
(Übrigens ist mein Englisch falsch: "Lieferant" heißt "supplier", nicht "deliverer" - also macht das blos nicht nach!)
Vorraussetzung zum Verständnis ist ein Verständnis der relationalen Datenmodellierung, also was bedeutet Beziehung (alias "Relation"), was ist eine 1:n-Relation, was eine m:n-Relation, und warum ist relationale Datenmodellierung so viel toller als wenn man einfach Objekte schafft, die selbst wieder Listen weiterer Objekte enthalten.
Vier-Views-Theorie
naja, ich unterscheide 4 grundlegende Typen, wie man komplexe Daten präsentieren kann (also anzeigen + der User kann was damit tun):
- DetailView: Labels, Text-/Check-boxen, DateTimePicker etc zeigen/editieren Werte eines zuvor ausgewählten Datensatzes (klassische "Eingabe-Maske")
- ParentChild-View: links wird aus der ParentTable ein Datensatz ausgewählt, und rechts zeigt eine zweite Tabellen-Ansicht alle damit verknüpften Child-Datensätze
- JoiningView: ComboboxColumns holen Werte übergeordnet verknüpfter Tabellen in eine TabellenAnsicht hinein.
- m:n - View: Kombination ParentChild - JoiningView: links die ParentTable, rechts Childrows. Mittels Comboboxen werden Werte einer anderen übergeordneten Tabelle hineingeholt.
Sodass in Summa die indirekte Beziehung zweier übergeordneter Tabellen sichtbar wird - ihre m:n-Relation.
Jedenfalls wesentlich an den Views ist auch, dass man sie nach Belieben und Erfordernis miteinander kombiniert, und damit eine unerhörte Vielfalt an Präsentations-Möglichkeiten erhält.
Beispiel-Datenmodell
Man denke an ein Kaufhaus - extrem verkürzt: es gibt Artikel, ArtikelKategorien und Lieferanten - mehr nicht.
Das Modell ist auch schnell notiert:
Category -> Article <- Delivereroder als Dataset-Bildle:
Artikel ist sowohl den Kategorien als auch den Lieferanten untergeordnet: eine Kategorie enthält viele Artikel, ein Lieferant liefert viele Artikel.
Und andersrum betrachtet: jeder Artikel verweist mittels ForeignKey auf genau eine Kategorie, und auf genau einen Lieferanten.
Also zwei 1:n-Relationen mit gemeinsamer untergeordneter Tabelle, und sowas ist inne Datenbänkerei halt als m:n-Relation bekannt (eine Kategorie enthält Artikel vieler Lieferanten, und ein Lieferant liefert Artikel vieler Kategorien)
Wie gesagt: Wer diesen Begrifflichkeiten (1:n - m:n - Relation) nicht folgen kann: Relationale Datenmodellierung
Andernfalls mögen die folgenden Filmle eine vielleicht beeindruckende Zielvorstellung und Motivation geben. Aber praxisrelevant, also dass man die gezeigten Features in eigenen Projekten dienstbar hat, ist das erst, wenn das mit den Relationen richtig verstanden ist, weil darauf baut es auf.
Übrigens jede nicht-triviale Sql-Datenbank baut ebenfalls darauf auf.
Die Filme
Film I - Datamodel Hier wird das Datenmodell aufgesetzt, und auch die Datengenerier-Methode angedeutet, die dieses Modell adäquat füllt, insbesondere die Artikel-Table, (nämlich aus zwei sich teilweise überschneidenden Lieferanten- und Kategorie-Gruppen).
Die Generiererei ist eiglich zu kompliziert, ums im Film gleich zu kapieren, aber sie ist im Code-Download drinne, und ist mir wichtig zu zeigen, dass das typisierte Dataset über einen Haufen speziell generierte Methoden verfügt, mit denen man eigentlich jeden Standard-Zugriff in streng typisierter Manier ausführen kann - natürlich auch das Adden von neu generierten typisierten DataRows.
Also beim Zugriff aufs Dataset willich nix sehen mit:
myDataset.BlablaTable.Rows(CInt(grottenRow("HoffeEsGibtDieseSpalte")) odersowas (achtung - Beispiel ausse Praxis):
Dataset, DataTable, DataRow nie nie wieder benutzen braucht - also wo As DataRow im Code auftaucht - da läuft schon was falsch!Wir haben
ArticleRows, CategoryRows, DelivererRows in unserem Dataset, auf die untypisierte Basisklasse DataRow können und sollten wir vollständig verzichten!Film II - RawView erstellt eine erste Roh-Ansicht aller 3 Tabellen, ohne jede Fisematente. Sowas braucht man eiglich immer, um schnell zu gugge, ob Daten da sind, oder um halt mal welche eingeben zu können.
Film III - JoiningView zeigt endlich den ersten der 4 Views, nämlich den JoiningView, also ein Article-DatagridView, bei dem ComboboxColumns Werte der übergeordneten Tabellen mit "hinein-joinen" (nämlich
Category.Name und Deliverer.Name)Der Name "JoiningView" ist in Analogie zur Sql-InnerJoin-Abfrage gewählt, denn ein JoiningView zeigt genau die Daten an, die auch ein Sql-InnerJoin über mehrere Tabellen anliefern würde.
Er leistet aber wesentlich mehr, denn er ermöglicht dem User, Änderungen vorzunehmen und zurückzuspeichern - eine Option, die beim Sql-Innerjoin prinzipiell ausgeschlossen ist.
Film IV - DetailView zeigt eine schlichte Liste der Artikel(-Namen), und man kann einen Artikel auswählen, und bekommt all seine Properties in ausführlichen Einzel-Controls präsentiert.
Der hier gezeigte DetailView geht aber über einen schlichten DetailView hinaus, denn er enthält auch einen Joining-Part, nämlich Comboboxen, die (wieder)
Category.Name und Deliverer.Name mit-präsentieren.Es handelt sich hier also um einen kombinierten View, und das ist ebenfalls Kern-Aussage der 4 View-Theorie, nämlich dass die vier Grundtypen beliebig kombinierbar sind.
Film V - ParentChild-View zeigt links alle Kategorien, und rechts alle Artikel, die der links gewählten Kategorie angehören.
Obwohl sehr einfach zusammengeklickst, beeindruckt dieser View doch mehr als ein Joining-View, weil über das Databinding werden immer alle angezeigten Artikel ausgetauscht, wenn man eine annere Category wählt.
FilmVI - m:n-View - habe ich gleich in beide Richtungen implementiert: Einmal kannman eine Kategorie wählen, und sieht alle Artikel, inklusive Lieferant.
Beim View in Gegenrichtung kann man dann einen Lieferanten wählen, und sieht alle Artikel, die er liefert, inklusive ihrer jeweiligen Kategorie.
Son m:n-View kombiniert also den ParentChildView (Film V) mittm JoiningView (Film III).
Weiterführende Links
- Im hiesigen Tut wird ja nur Designer-Arbeit an Datenmodell und Präsentation gezeigt. Laden und Speichern und Datenverarbeitung in typisierter Manier findet sich auf Daten laden, speichern, verarbeiten
- Zu den sehr mächtigen Möglichkeiten der BindingSource-Klasse findet sich auf DataExpressions so allerlei.
- Auf englisch habe ich eine 3-teilige Artikel-Reihe verzapft, die einen großen Bogen spannt: relationalen Grundlagen, Design-Prinzipien, Dataset-Designer, Databinding, ObjectBrowser bis hin zu einem Beispiel nicht-trivialer Daten-Verarbeitung und -Präsentation.
Was hier also eher schlaglicht-artig in Filmen kurz vorgeturnt wird, ist dort in einer zusammenhängenden Linie behandelt, gründlicher, und mit mehr Hintergrund.
Würde mich auch freuen, wenns der eine oder andere up-rated - das Code-Project-Rating-System hat großen Einfluss darauf, wieviel Beachtung einem Artikel widerfährt.
Hier die Sample-Solution der Videos als Download:
(Übrigens ist mein Englisch falsch: "Lieferant" heißt "supplier", nicht "deliverer" - also macht das blos nicht nach!)
Dieser Beitrag wurde bereits 26 mal editiert, zuletzt von „ErfinderDesRades“ ()
 . Weil den Anwendungs-Prototyp, den man sich zusammenklickst, muss man natürlich verstehen, modifizieren und drauf aufbauen, dass eine wirkliche Anwendung draus wird.
. Weil den Anwendungs-Prototyp, den man sich zusammenklickst, muss man natürlich verstehen, modifizieren und drauf aufbauen, dass eine wirkliche Anwendung draus wird.



